ESXi环境下实现RAID磁盘健康状态监控
ESXi_RAID_Exporter
Github:https://github.com/luanxinchen/ESXi_RAID_exporter
这是一个运行在ESXi宿主机底层Shell环境上的探针脚本,使用Megacli获取阵列卡Raid信息及物理磁盘信息,将获取到的信息格式化POST到Pushgateway,Prometheus从Pushgateway获取数据后,配合Grafana和Alertmanager对ESXi主机Raid下的硬盘健康状态进行实时监控及预警,协助运维人员快速响应,及时排除故障。
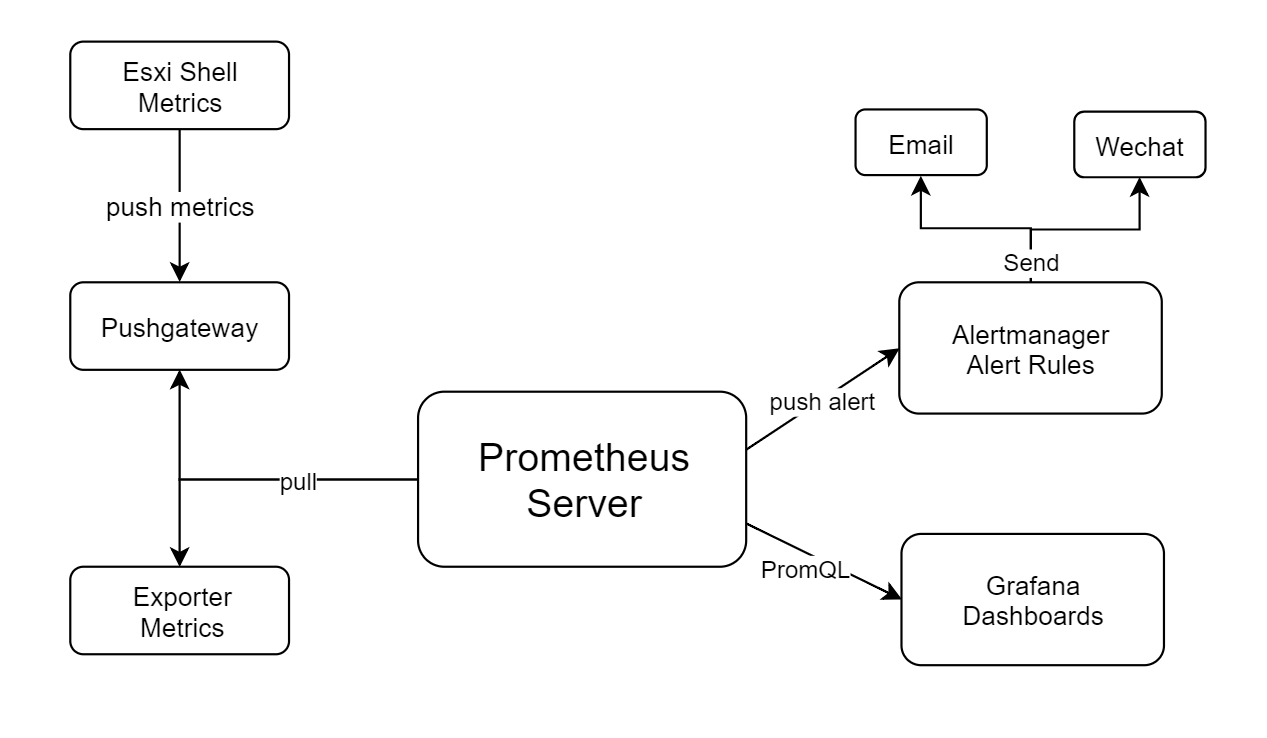
监控环境部署
ESXi Shell
1) 部署准备
进行部署前需要开启ESXi宿主机的Shell、SSH和CIM,(开启CIM让ESXI与其他主机通讯)
登陆vCenter或vClient,选择需要开启Shell的主机,点击配置
选择“安全配置文件”——“服务”——“属性”,打开服务属性对话框,找到ESXi Shell点击“选项”,选择“手动启动和停止”,点击“启动“然后确定。
SSH、CIM开启方法同上。
注意:ESXi防火墙需打开vCenter Update Mnager,允许9000-9100端口通过,否则无法与Pushgateway建立连接
其他环境需求:Prometheus、Pushgateway、Grafana、Alertmanager的部署在此不做赘述,请参考其他部署资料
2) 安装Megacli
首先SSH到ESXi主机,将vmware-esx-MegaCli-8.07.07.vib上传到tmp目录,依次执行命令
esxcli software vib install -v /tmp/vmware-esx-MegaCli-8.07.07.vib --no-sig-check
cp /opt/lsi/MegaCLI/libstorelib.so /lib/libstorelib.so
/opt/lsi/MegaCLI/MegaCli -v -nolog
输出结果为版本信息表示安装成功
3) 运行脚本
上传raid_exporter.py到监控主机,执行vi raid_exporter.py,找到
url = 'http://172.16.2.30:9091/metrics/job/raid_exporter/instance/172.16.1.92'
将172.16.2.30:9091修改为Pushgateway主机的地址端口,172.16.1.92修改为ESXi主机的IP地址或自定义一个主机名称,用于后续操作区分实例。
待Prometheus和Pushgateway部署完成后,将脚本放入后台执行:
nohup python raid_exporter.py &
PS:这里测试使用的python版本为2.7.8
4) 查看Metrics
脚本执行后,打开pushgateway可以看到当前获取到的metrics
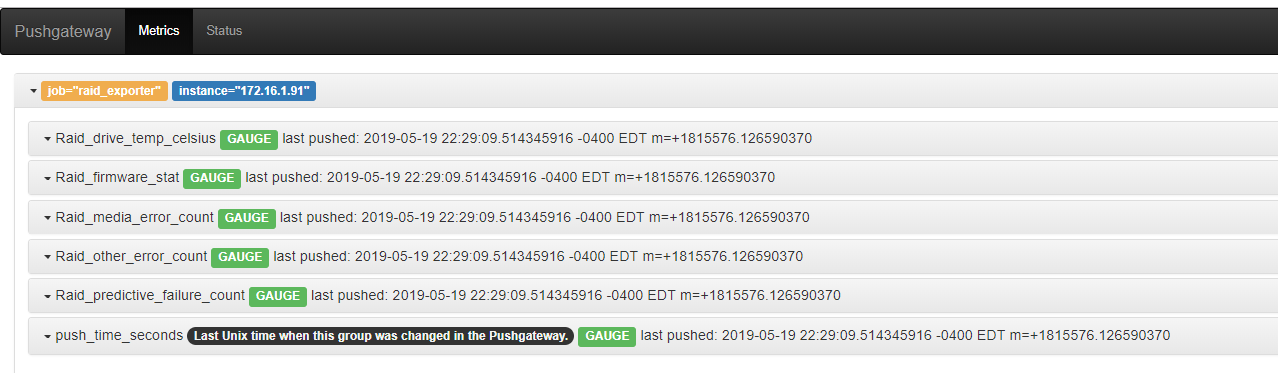
脚本默认每隔30分钟push一次数据,如需修改请编辑raid_exporter.py文件,找到time.sleep(1800),将1800修改为需要调整的时间换算为秒即可。
Alertmanager
使用alertmanager需要在prometheus中预先配置rule文件,编辑prometheus.yml:
alerting:
alertmanagers:
- static_configs:
- targets: ["localhost:9093"] #alertmanager监听地址端口
rule_files:
- "rule.yml" #rule文件需放在prometheus根目录
增加以上内容,重启prometheus生效。
配置alertmanager配置文件,编辑alertmanager.yml:
global:
smtp_smarthost: 'smtp.exmail.qq.com:587' #邮件服务器
smtp_from: 'guardian@transwarp.io' #报警邮件账户
smtp_auth_username: 'guardian@transwarp.io' #同上
smtp_auth_password: '***********' #邮箱账户密码,一般为客户端授权码
smtp_require_tls: true
templates:
- '/usr/work/alertmanager-0.17.0.linux-amd64/template/email.tmpl' #邮件模板
route:
group_by: ['alertname']
group_wait: 10s #首次警报触发后多久发送邮件
group_interval: 30s #在发送新警报前等待多长时间
repeat_interval: 1m #重复发送报警邮件的周期,建议设置长间隔,否则引起邮件轰炸
receiver: 'email'
receivers:
- name: 'email'
email_configs:
- to: '1102026400@qq.com' #报警邮件收件人
headers: { Subject: "[WARN] Prometheus报警邮件" } #报警邮件标题
配置完成后启动alertmanager,当警报触发时,会收到来自alertmanager的报警邮件
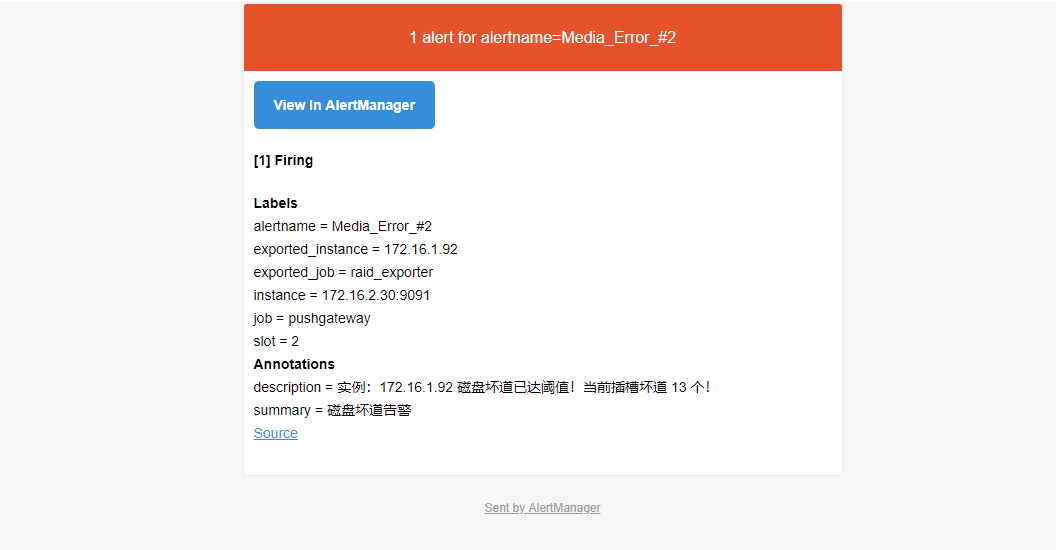
Grafana
将仪表盘json文件导入到Grafana中,打开仪表盘界面:
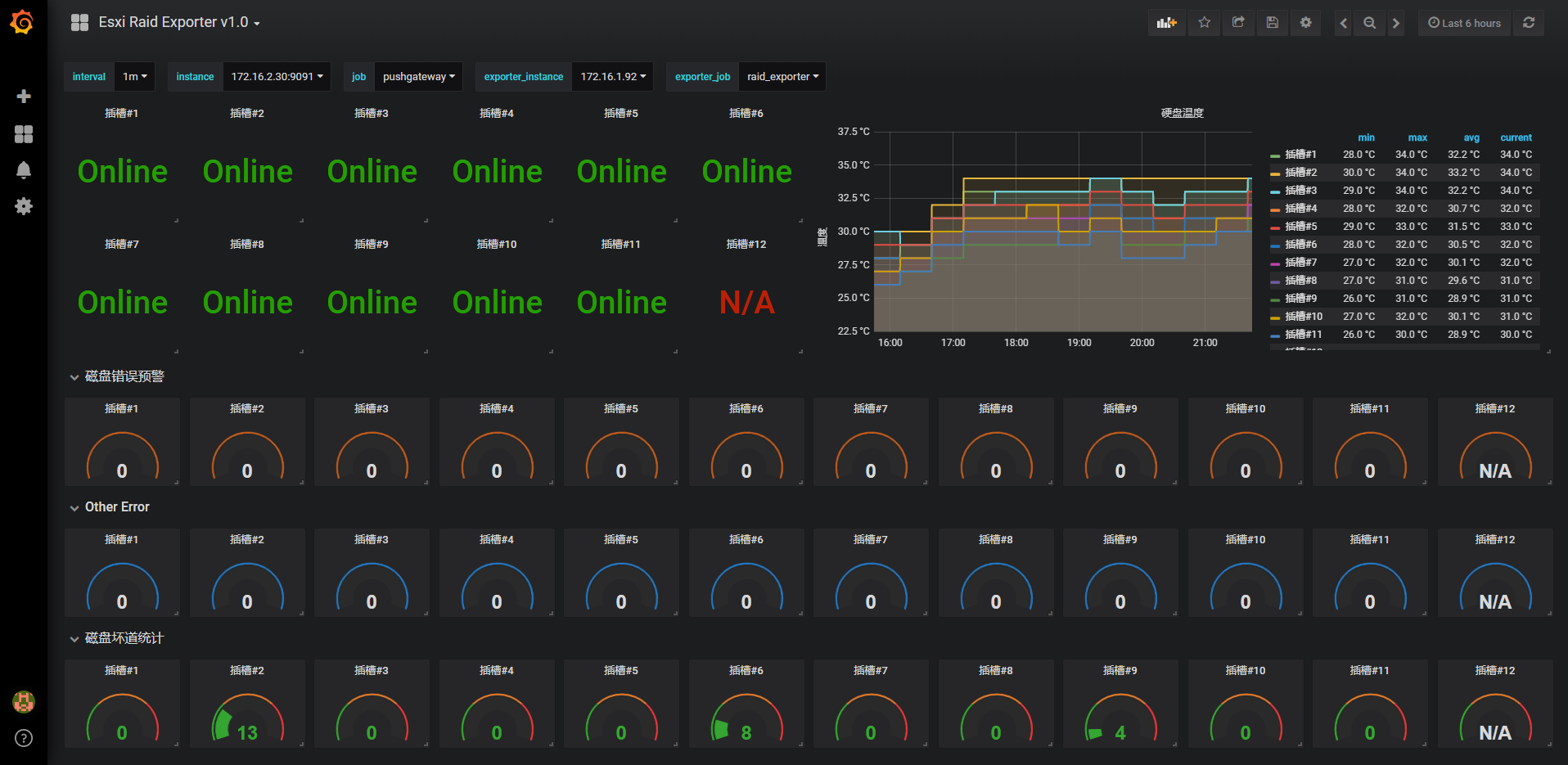
在仪表盘上方exporter_instance选择脚本部署的实例,即可展示该实例被监控的数据。
监控数据分析
1) 硬盘状态:
- Unconfigured Good :未配置好,RAID控制器可访问的驱动器,但未配置为虚拟驱动器或热备份
- Online:在线
- Rebuild :重建,正在写入数据的驱动器,以恢复虚拟驱动器的完全冗余
- Failed :失败
- Unconfigured Bad:未配置的坏驱动器;固件检测到不可恢复的错误;驱动器无法初始化Unconfigured Good或驱动器
- Missing:丢失,驱动器在线,但已从其位置移除
- Offline:脱机,驱动器是虚拟驱动器的一部分,但在RAID中具有无效数据或未配置。
- Hot Spare:热备份
- None:具有不支持标志集的驱动器。具有未配置的良好或离线驱动器,完成了搬迁作业的准备工作。
- N/A:表示插槽未启用,未插入任何磁盘。
2) 硬盘温度
- 检测硬盘温度
3) 磁盘错误预警
- 数值不为0时表示磁盘处于危险状态,需要立即更换硬盘!
- N/A:表示插槽未启用,未插入任何磁盘。
4) 磁盘坏道统计
- 数值大于0时表示磁盘已经出现坏道,请尽快更换硬盘!
- 数值一旦大于阈值,需要立即更换硬盘!
- N/A:表示插槽未启用,未插入任何磁盘。
5) 磁盘其他错误
- 数值不为0时可能需要重新插拔硬盘,重新获取数据!
- N/A:表示插槽未启用,未插入任何磁盘。
故障处理
-
打开ESXi Shell或SSH到故障主机
-
查看物理磁盘信息
/opt/lsi/MegaCLI/MegaCli -pdlist -aALL -nolog -
查看逻辑磁盘信息(包含Raid级别信息)
/opt/lsi/MegaCli/MegaCli -LDInfo -Lall -aALL -nolog查看Raid设置信息以及对应Disk信息
/opt/lsi/MegaCLI/MegaCli -cfgdsply -a0 -
在输出结果中查找包含故障信息的段,定位故障硬盘
- Slot Number表示插槽编号
- Drive's position表示磁盘分组位置
- Inquiry Data包含设备型号和序列号,可在拔盘后进行核对
- RAID Level表示Raid级别信息
-
定位到故障磁盘后进行更换
-
由于Raid缓存特性,硬盘更换后,error计数器不会立即重置,需要重启服务器方可清零
MegaCLI命令收集
#/opt/lsi/MegaCli/MegaCli -LDInfo -Lall -aALL查看逻辑磁盘信息#/opt/lsi/MegaCli/MegaCli -AdpAllInfo -aALL查看raid卡设置信息#/opt/lsi/MegaCli/MegaCli -PDList -aALL查看物理硬盘信息#/opt/lsi/MegaCli/MegaCli -AdpBbuCmd -aAll查看电池信息#/opt/lsi/MegaCli/MegaCli -FwTermLog -Dsply -aALL查看raid卡日志#/opt/lsi/MegaCli/MegaCli -AdpAllInfo -aAll【显示所有适配器信息】#/opt/lsi/MegaCli/MegaCli -AdpBbuCmd -GetBbuStatus -aALL【显示BBU状态信息】#/opt/lsi/MegaCli/MegaCli -AdpBbuCmd -GetBbuCapacityInfo -aALL【BBU容量】#/opt/lsi/MegaCli/MegaCli -AdpBbuCmd -GetBbuDesignInfo -aALL【BBU设计参数】#/opt/lsi/MegaCli/MegaCli -AdpBbuCmd -GetBbuProperties -aALL【当前BBU属性】#/opt/lsi/MegaCli/MegaCli -cfgdsply -aALL【Raid卡型号,Raid设置,Disk信息】